PgPool: How to setup PostgreSQL Load Balancer on Kubernetes Cluster
A database load balancer is a tool that helps distribute incoming database traffic evenly among different servers. Load balancers use algorithms such as round-robin or least-connections to decide how to assign incoming queries to servers.

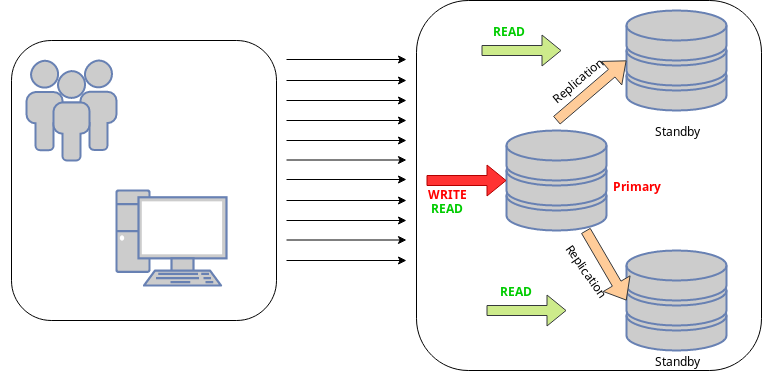
Introduction
Hey there! If you've been looking to learn more about database load balancing and PgPool, you've come to the right place. In this article, we'll break down the ins and outs of PgPool, provide examples, and give you in-depth technical details for a clearer understanding. Let's dive right in!
We also have an in-depth technical article about PgBouncer: PostgreSQL Database Pooling. Check this out!

Database Load Balancers: What Are They and How Do They Work?
A database load balancer is a tool that helps distribute incoming database traffic evenly among different servers. Load balancers use algorithms such as round-robin or least-connections to decide how to assign incoming queries to servers. By distributing traffic, no single server gets overloaded, and your system can handle more users and queries without a hitch.
For example, imagine a PostgreSQL database cluster with three read replicas. A round-robin load balancing algorithm would distribute read queries sequentially among the replicas in a cyclical manner, ensuring that each replica gets an equal share of the workload.
Load balancers work as reverse proxies, sitting between client applications and backend servers. They receive incoming requests from clients and forward them to the appropriate server, based on the load balancing algorithm. Load balancers may also monitor server health, removing unresponsive servers from the pool and redistributing traffic accordingly.
The Need for Database Load Balancers Solving Real-World Problems
In our fast-paced, data-driven world, databases need to be agile and reliable. As your application grows, you might find that your database struggles to keep up with increasing traffic. That's where a load balancer comes in handy!
For example, consider an e-commerce website that experiences a surge in traffic during a sale event. Without a load balancer, the database server might get overloaded with requests, leading to slow response times and even downtime. A load balancer helps distribute the traffic among multiple servers, ensuring smooth performance even during peak traffic.
The Perks of Using Database Load Balancers
Database load balancers offer several benefits that can improve the performance and reliability of your application. Some of the key advantages include:
- Better performance: Load balancers help ensure that each server works optimally, reducing query response times. For example, a load balancer can distribute read-heavy workloads across multiple replicas, allowing for faster query execution and reduced latency. This is particularly important for applications with real-time data processing requirements, where low latency is crucial.
- Improved scalability: As your app grows, you can easily add more servers to your load-balanced system. This makes it easy to accommodate increased traffic without causing bottlenecks. By distributing the load, your application can scale horizontally, enabling it to handle more concurrent users and requests.
- High availability: If one server goes down, a load balancer can redirect traffic to healthy servers, minimizing downtime. For instance, a load balancer can monitor the health of the servers and automatically remove unresponsive servers from the pool. This ensures that your application remains highly available even in the face of server failures, and it helps maintain a consistent user experience.
- Better resource utilization: Load balancers can help you make the most of your existing infrastructure by ensuring that all servers are being used efficiently. This can result in cost savings, as you may not need to add as many new servers to handle increased traffic.
Introducing PgPool: A Popular Database Load Balancer for PostgreSQL
PgPool is an open-source middleware solution that sits between your PostgreSQL clients and servers. It helps you manage and distribute your database traffic, making it a top choice for load balancing with PostgreSQL. PgPool is highly configurable, allowing you to fine-tune its behavior to suit your specific use case and performance requirements.
Key Features of PgPool
PgPool comes packed with cool features, such as:
- Connection pooling: PgPool reduces connection overhead by reusing existing connections to the database. This can significantly improve performance, especially in situations with a high number of concurrent clients. Connection pooling also helps reduce the number of open connections to the database, which can lead to better resource management on the database server.
- Replication and Load Balancing: PgPool can distribute read queries across multiple servers for better performance. For example, it can route SELECT queries to read replicas while directing write queries to the primary server. This ensures that write-heavy operations don't slow down read-heavy operations, resulting in a more balanced system overall.
- Automated Failover: If a server fails, PgPool automatically redirects traffic to healthy servers, keeping your app up and running. This ensures that your application remains highly available even in the face of server failures. In addition to detecting failures, PgPool can also perform automatic recovery actions, such as promoting a replica to primary in case the primary server fails.
- Query Caching: PgPool offers a built-in query cache that can store the results of frequently executed queries, reducing the load on your database servers. This can lead to faster response times and improved performance, particularly for read-heavy workloads.
PgPool Alternatives: Exploring Other Load Balancing Options
While PgPool is a popular choice for PostgreSQL load balancing, there are other options you might consider, such as:
- HAProxy: A high-performance load balancer that supports various load balancing algorithms and can be used with PostgreSQL. HAProxy provides advanced features like SSL termination, health checks, and server weighting, making it a powerful alternative to Pgpool.
- PGBouncer: A lightweight connection pooler for PostgreSQL that can help manage connections and improve performance, but lacks advanced features like replication and failover support. PGBouncer is a good option if you need a simpler solution focused primarily on connection pooling.
Installing PgPool on Kubernetes Cluster
Setting up PgPool on a Kubernetes Cluster is quite simple. Let's say you have three PostgreSQL servers:
- Server A (IP: 33.333.333.333): Primary server, which handles both Write and Read requests
- Server B (IP: 33.333.333.444): As a replica of Server A. Standby server, which only handles Read requests
- Server C (IP: 33.333.333.555): As a replica of Server A. Standby server, which only handles Read requests
All with credentials:
- Username: admin
- Password: xxx
Create a file called deployment.yml. This file will include deployment and service configurations for Kubernetes, as well as the PgPool configuration in the form of a ConfigMap.
Install it to Kubernetes Cluster
~$ kubectl apply -f deployment.ymlNow, you can refer to PgPool's service when connecting application to database. Your PostgreSQL URI should look like:
postgres://admin:xxx@pgpool.default:5432/example_dbAbout 8grams
We are a small DevOps Consulting Firm that has a mission to empower businesses with modern DevOps practices and technologies, enabling them to achieve digital transformation, improve efficiency, and drive growth.
Ready to transform your IT Operations and Software Development processes? Let's join forces and create innovative solutions that drive your business forward.
Subscribe to our newsletter for cutting-edge DevOps practices, tips, and insights delivered straight to your inbox!