How to setup persistent storage with NFS on GKE (Google Kubernetes Engine), the proper way
A Persistent Volume (PV) in Kubernetes is a storage resource abstraction that provides a way to store and manage persistent data for applications running in a Kubernetes cluster.

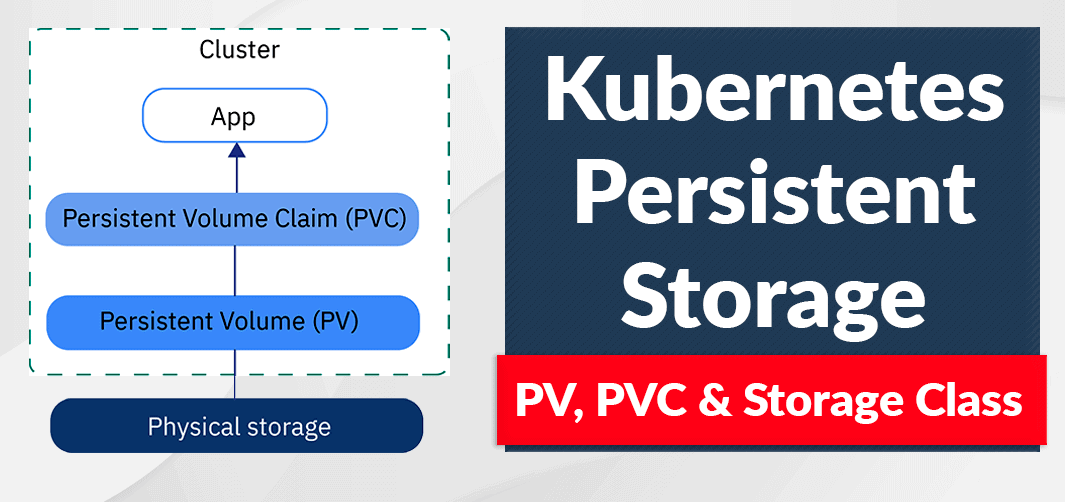
A Persistent Volume (PV) in Kubernetes is a storage resource abstraction that provides a way to store and manage persistent data for applications running in a Kubernetes cluster. Kubernetes uses PVs to decouple the storage infrastructure from the applications, allowing for more efficient and flexible storage management.
In Kubernetes, applications are typically deployed as containers inside Pods. By default, containers have an ephemeral file system, which means the data stored inside the container is lost when the container is terminated or the Pod is deleted. This ephemeral nature is not suitable for applications that require persistent storage, such as databases or file servers. Persistent Volumes address this need by providing a mechanism to store data outside the container's lifecycle.
Here are some key concepts related to Persistent Volumes in Kubernetes:
- Persistent Volume (PV): A PV is a storage resource in a cluster, provisioned by an administrator or dynamically by a storage provider, and represents a physical or networked storage device. PVs have a lifecycle independent of any individual Pod or container.
- Persistent Volume Claim (PVC): A PVC is a request for storage by a user, which can be thought of as a "claim" to a specific amount of storage on a PV. PVCs are created by users to allocate storage resources for their applications. When a PVC is created, Kubernetes binds it to an appropriate PV, either pre-provisioned by an administrator or dynamically created by a storage provider.
- Storage Class: A Storage Class is a way to define different classes or categories of storage in a Kubernetes cluster. Storage Classes can be used to configure the storage provider, set parameters for dynamic provisioning, and define the quality of service (QoS) attributes for a specific storage type.
- Dynamic Provisioning: Dynamic provisioning is a feature that allows Kubernetes to automatically create PVs on-demand when a user creates a PVC. This is done through the use of Storage Classes and storage provider plugins.
To summarize, Persistent Volumes in Kubernetes provide a way to manage and allocate persistent storage for containerized applications. They decouple storage infrastructure from applications, allowing for more flexible and efficient storage management. PVs and PVCs work together to allocate storage resources, while Storage Classes and dynamic provisioning help to automate and manage storage provisioning more effectively.
Drawbacks of using native PV in Kubernetes
While using native PV in Kubernetes is the easiest way to get started with persistent storage in Kubernetes, it comes with some drawbacks that you should consider when using it.
- Backup and Disaster Recovery: Native PVs do not include built-in backup and disaster recovery mechanisms. You'll need to implement and manage these processes separately, which can be complex and time-consuming.
- Cluster Lock-in: Native PVs are always attached to the cluster. When your cluster is destroyed, your PVs will also be destroyed, resulting in data loss.
This does not mean that using native PVs in Kubernetes is inherently bad. You can still rely on native PVs for tasks like caching or generating configuration files. However, if you need to store important files, such as documents or user photos, native PVs may not be the best option. The better choice would be to use storage services like GCS on GCP or AWS S3. If you can utilize these cloud services, that's great. However, if you can't for reasons such as cost (they can be quite expensive) or lack of access to subscriptions, NFS can serve as a viable alternative.
What is NFS?
Network File System (NFS) is a distributed file system protocol that enables multiple clients to access shared files and directories on a remote server over a network. Developed by Sun Microsystems in the 1980s, NFS allows users to treat files and directories on remote servers as if they were stored locally on their own systems.
NFS operates on a client-server model, where the server exports (shares) directories and files to clients, which then mount the shared resources, making them available for reading and writing. NFS uses Remote Procedure Call (RPC) and runs on top of the Internet Protocol (IP) to enable communication between clients and servers.
Here are some key features of NFS:
- Transparency: NFS enables users to access remote files as if they were stored locally on their systems. This transparency simplifies file and directory management, making it easier to work with shared resources.
- Platform independence: NFS is platform-independent, allowing clients and servers to run on different operating systems and architectures. This versatility makes NFS suitable for heterogeneous environments with a mix of operating systems.
- Scalability: NFS can be used to share files and directories across large networks, enabling organizations to scale their storage infrastructure as needed.
- Stateless design: NFS uses a stateless design, which means the server does not maintain information about the client's state between requests. This allows for better fault tolerance and recovery, as the server can continue to serve requests even if a client crashes or disconnects.
- Caching: NFS clients use caching to improve performance by storing recently accessed data locally. This reduces the need for repeated requests to the server, which can help decrease network traffic and server load.
- Security: NFS supports various security mechanisms, such as Network File System version 4 (NFSv4) with Kerberos authentication, to provide secure access to shared resources. However, earlier versions of NFS have weaker security measures, and additional configurations may be necessary to ensure a secure environment.
NFS is commonly used in Unix and Linux environments for sharing files and directories between systems. It can also be used with other operating systems, such as Windows and macOS, with the appropriate client and server software. In the context of Kubernetes, NFS can be used as a storage backend for Persistent Volumes, providing a shared file system for containerized applications.
Using NFS on GKE
In this article, we will create an example of using NFS in GKE. It assumes you are using Terraform as a Cloud Provisioner, but you can always do this using Google Cloud Console as well.
Creating Disk
The first step is to create a disk, which can be done with Google Compute Disk.
Here, we will create a Google Compute Disk (GCD) called storage-nfs, which will reside in the ap-southeast2-a zone. GCD is only available as a zonal service, not regional, but that's suitable for most cases. Another important detail is setting the disk size to 10 GB.
Apply Terraform to create GCD:
~$ terraform apply -auto-approveCreating NFS Service and Deployment
The next step is to create an NFS Service and Deployment. This will act like a normal Service and Deployment on Kubernetes. The deployment will create NFS Server Pods, and the service will sit in front of those pods.
Because GCD is zonal, we need to ensure that the Pods created by the Deployment above will be created in a Node that has the same zone as GCD. Therefore, we use nodeAffinity and asia-southeast2-a as the Node Selector.
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- asia-southeast2-aAnother crucial detail is setting /exports as the volume's mount path. This path is used by NFS Server Pods as a shared directory with GCD. If you use another path, you will lose all of your data when the NFS Server Deployment is restarted.
volumeMounts:
- mountPath: /exports
name: nfs-pvcLastly, we use the GCD we created before (storage-nfs) as volumes for our NFS Server.
volumes:
- name: nfs-pvc
gcePersistentDisk:
pdName: storage-nfs
fsType: ext4Deploy it to the Kubernetes Cluster:
~$ kubectl apply -f nfs.yamlCreating PV and PVC
The final step is creating a PV and PVC. This PV will use the NFS we created earlier.
As you can see above, we set the capacity to the same size as our GCD's size: 10 GB and set the NFS Server to the NFS Service we created before. Deploy it to the Kubernetes Cluster:
~$ kubectl apply -f pv.yamlApplication Deployment
After the NFS Server is set up, we can use it as a volume for our application. In the example below, we create an Uptime Kuma deployment. Uptime Kuma requires a volume to store its SQLite DB file in the /app/data directory.
Deploy it:
~$ kubectl apply -f uptime.yamlDone! You now have an NFS Server running on your Kubernetes Cluster that utilizes Google Compute Disk as its persistent disk storage. Additionally, you have a running application with a volume mounted to that PV using the NFS Server.
About 8grams
We are a small DevOps Consulting Firm that has a mission to empower businesses with modern DevOps practices and technologies, enabling them to achieve digital transformation, improve efficiency, and drive growth.
Ready to transform your IT Operations and Software Development processes? Let's join forces and create innovative solutions that drive your business forward.
Subscribe to our newsletter for cutting-edge DevOps practices, tips, and insights delivered straight to your inbox!